An investigation of streaming non-autoregressive sequence-to-sequence voice conversion
Tomoki Hayashi (TARVO Inc. / Nagoya University)
Kazuhiro Kobayashi (TARVO Inc. / Nagoya University)
Tomoki Toda (Nagoya University)
Abstract
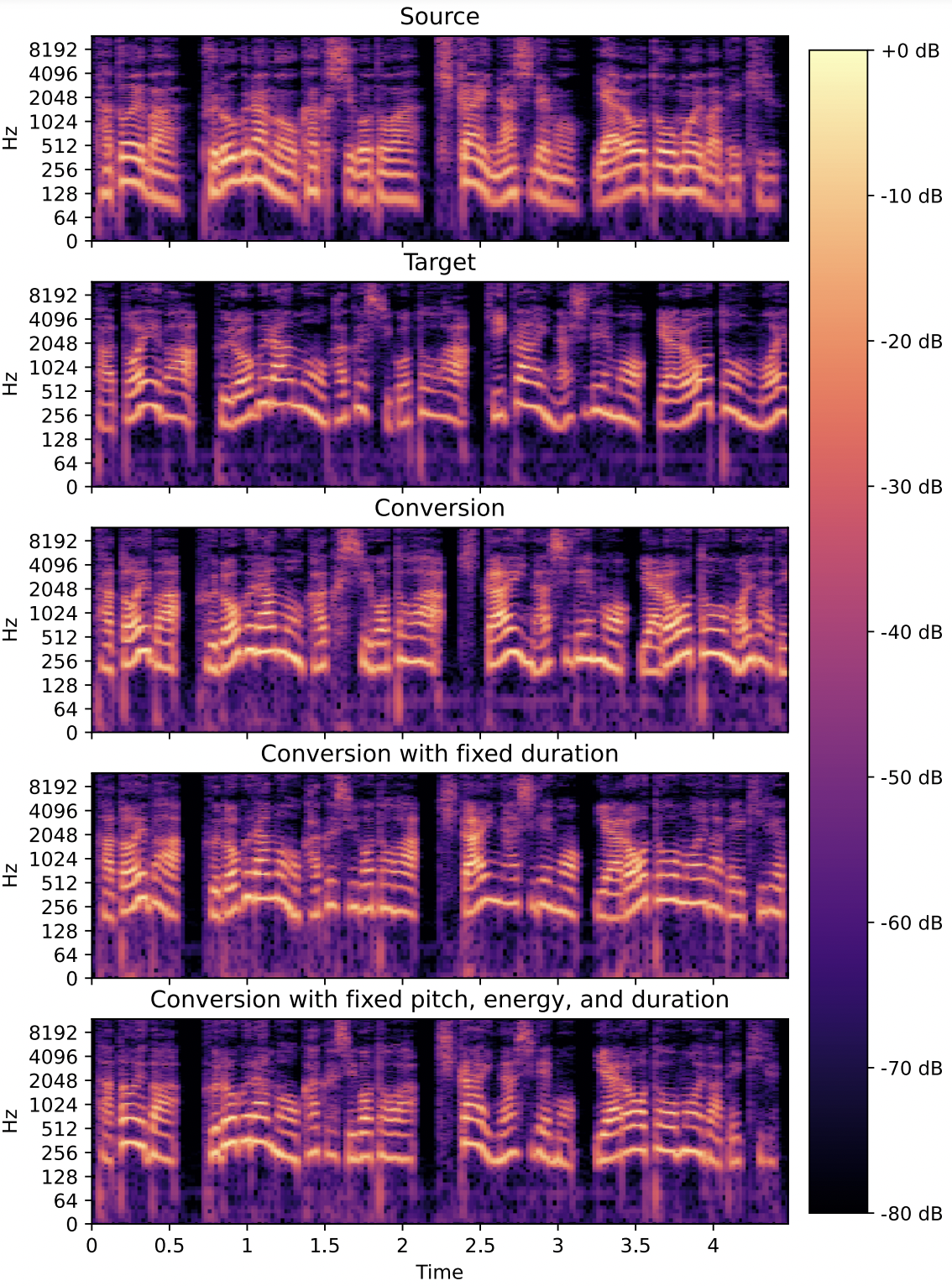
Recent advances in sequence-to-sequence (S2S) models have improved the quality of voice conversion (VC), but it requires an entire sequence to perform inference, which prevents using it in real-time applications. To address this issue, this paper extends the non-autoregressive (NAR) S2S-VC model to enable us to perform streaming VC. We introduce streamable architecture such as a causal convolution and a self-attention with causal masking for the FastSpeech2-based NAR-S2S-VC model. This streamable architecture also tries to convert durations, which are kept as is in conventional real-time VC methods. To further improve the performance of the streaming VC model, we utilize an instant knowledge distillation with a dual-mode architecture, which performs non-causal and causal inference by sharing the network parameters. Through the experimental evaluation with Japanese parallel corpus, we investigate the impact on performance caused by the streamable architecture. The experimental results reveal that the use of future context frames increases latency, but it improves the conversion quality, and that difference in the speaking rate affects the performance of streaming inference.