ESPnet2で始めるEnd-to-End音声処理
Author: 林 知樹(Tomoki Hayashi)
Github: @kan-bayashi
以下の内容はESPnet v.0.9.4の内容に基づきます。
バージョンの更新により、内容が大きく変化する可能性があります。
目次
はじめに
本記事は、音響学会誌で刊行予定の解説文論「End-to-End音声処理の概要とESPnet2を用いたその実践」の付録です。上記と合わせて読んでいただけるとより理解が深まると思います。
本記事で出来るようになること
はじめに、本記事を読むことで出来るようになることを上げておきます。
- ESPnet2で事前学習された音声認識モデル / テキスト音声合成モデルを使って推論すること
- ESPnet2で提供されているレシピを使って音声認識モデル / テキスト音声合成モデルを学習すること
本記事ではEnd-to-End音声処理のアルゴリズムの詳しい説明は行わず、ツールの利用方法などの実践的な部分に焦点を当てます。
ESPnetとは?
ESPnetとは、End-to-End(E2E)型のモデルの研究を加速させるべく開発された、E2E音声処理のためのオープンソースツールキットです。ライセンスはApache 2.0で、商用利用も可能です。
ESPnetは、E2E型モデルを記述したPythonライブラリ部と、シェルスクリプトで記述されたレシピ部で構成されています。Pythonライブラリ部は、Define-by-Run方式のChainer及びPyTorchをニューラルネットワークエンジンとして利用しており、柔軟なモデルの記述・拡張を実現しています。レシピ部は、音声認識ツールキットKaldiの方式に基づいており、再現実験を行うために必要な全ての手順が一括で実行できるようになっています。
ESPnet2とは?
ESPnet2は、ESPnetの弱点を克服するべく開発された次世代の音声処理ツールキットです。コード自体はESPnetのリポジトリに統合されています。基本的な構成はESPnetと同様ですが、利便性と拡張性を高めるため以下のような拡張が行われています。
- Task-Design: FairSeqの方式を参考に、ユーザーが任意の新しい音声処理タスク(例: 音声強調、音声変換)を定義できるように。
- Chainer-Free: Chainerの開発終了に伴い、Chainerに依存していた部分を改修。
- Kaldi-Free: Kaldiに依存していた特徴量抽出部がPythonライブラリ内に統合。これにより、多くのユーザーが躓きやすいKaldiのコンパイルが不要に。
- On-the-Fly: 特徴量抽出やテキストの前処理などがモデル部に統合。学習時や推論時に逐次的に実行されるように。
- Scalable: CPUメモリの利用の最適化を行い、数万時間オーダーの超巨大データセットを用いた学習が可能に。さらに、マルチノードマルチGPU方式の分散学習をサポート。
2020年10月時点の最新バージョンv.0.9.4では、音声認識(ASR)、テキスト音声合成(TTS)、そして、音声強調(SE)のタスクがサポートされています。今後は、さらなるタスク(例: 音声翻訳、音声変換)がサポートされる予定です。以下では、ASRとTTSを中心に、その使い方を簡単に解説します。
環境構築
ESPnetは、主にUbuntuやCentOSなどのLinux環境での利用を想定しており、必要動作要件は以下の通りです。
- Python 3.6.1+
- GCC 4.9+
- CUDA 10.0+
- CuDNN 7+
- NCCL 2.0+(マルチGPU利用の場合のみ)
以下では、上記の動作要件を満たしたUbuntu 18.04におけるターミナル上での環境構築手順を示します。
まず、必要なリポジトリをGithubより取得します。
$ git clone https://github.com/kaldi-asr/kaldi.git
$ git clone https://github.com/espnet/espnet.git -b v.0.9.4
espnet/toolsに移動します。
$ cd espnet/tools
Kaldiへのシンボリックリンクを作成します。この際、Kaldiはコンパイルする必要はありません。
$ ln -s $(pwd)/../../kaldi .
CUDAに関する環境変数を設定します。
$ . ./setup_cuda_env.sh /usr/local/cuda
CUDAのインストール場所が/usr/local/cudaではない場合は適宜変更してください。
ここでは簡単のため、Anacondaを利用したPython環境をvenv/以下に作成します。
$ ./setup_anaconda.sh venv
既存のPython環境を利用したインストールも可能です。詳しくはインストールマニュアルを参照してください。
作成したPython環境内へ必要なライブラリのインストールを行います。
$ make
日本語TTSを利用したい場合は、追加でPyOpenJTalkのインストールを行います。
$ make pyopenjtalk.done
以上で環境構築は完了です。
以後の処理では、espnet/tools/venvに作成されたPython環境を利用した処理が前提となります。そのため、この環境に新たにPythonライブラリ等を追加したい場合には、追加のインストールの前に環境のアクティベートを行う必要があることに注意してください。作成した環境をアクティベートするにはespnet/tools内のactivate_python.shをカレントシェルで読み込みます。
$ . ./activate_python.sh
事前学習モデルを利用した推論
ESPnet2では、研究データ共有リポジトリであるZenodoと連携していて、様々な事前学習モデルを簡単に試すことができます。また、試すだけではなく、Zenodoへと登録を行うことで、任意のユーザーが事前学習モデルをアップロードすることも可能です。
以下では、JSUTコーパスを用いて事前学習されたTTSモデルFastSpeech2による推論を実行するPythonコードの例を示します。
from espnet_model_zoo.downloader import ModelDownloader
from espnet2.bin.tts_inference import Text2Speech
# Create E2E-TTS model instance
d = ModelDownloader()
text2speech = Speech2Text(
# Specify the tag
d.download_and_unpack("kan-bayashi/jsut_fastspeech2")
)
# Synthesis with a given text
wav, feats, feats_denorm, *_ = text2speech(
"あらゆる現実を、全て自分の方へねじ曲げたのだ。"
)
ここで、wav、feats、及びfeats_denormはそれぞれ生成された波形、統計量で正規化された音響特徴量、及び逆正規化の音響特徴量を表します。デフォルトでは、音響特徴量から波形の変換はGriffin-Limによって行われますが、ParllelWaveGANなどのニューラルボコーダと組み合わせることも可能です。
また、こちらの例はGoogle Colabを利用したデモも公開しておりますので、ブラウザ上で簡単に試すことができます。興味がある方はコチラからアクセスしてみてください。以下のような音声を自由に生成できます。
ASRモデルの推論についても、ほぼ同一の手順で実行が可能です。以下では、Librispeechコーパスで学習されたASRモデルJoint CTC-Attention Transformerを利用した推論を実行するPythonコードの例を示します。
import soundfile as sf
from espnet_model_zoo.downloader import ModelDownloader
from espnet2.bin.asr_inference import Speech2Text
# Create E2E-ASR model instance
d = ModelDownloader()
speech2text = Speech2Text(
# Specify task and corpus
**d.download_and_unpack(task="asr", corpus="librispeech")
)
# Recognition with a given audio
wav, fs = sf.read("/path/to/sample.wav")
text, token, *_ = speech2text(wav)[0]
ここで、textとtokenはそれぞれ認識結果のテキストとトークンに分割された認識結果を表します。
上記の例からわかるように、ユーザーはわずか数行のコードで最新鋭のモデルを使った推論を実行することができます。これにより、デモシステムへの組み込みや、ベースラインとしての利用も簡単に行うことができます。より詳細な事前学習モデルの利用方法や公開されている事前学習モデルの一覧は、ESPnet Model Zooを参照してください。
レシピを利用したモデル構築
レシピとは、前処理、学習、評価といった実験に必要な全ての手順が含まれたシェルスクリプトのことを指します。ここでは、ASR及びTTSレシピに焦点を当て、その構造と使い方を概説します。
レシピの構造
ESPnet2では、全レシピが共通のテンプレートに基づいており、espnet/egs2内<corpus_name>/<task>の形式でまとめられています。例として、JSUTコーパスのASR及びTTSレシピのディレクトリ構造を以下に示します。
# ASR recipe # TTS recipe
egs2/jsut/asr1/ egs2/jsut/tts1/
- conf/ - conf/
- scripts/ - scripts/
- pyscripts/ - pyscripts/
- steps/ - steps/
- utils/ - utils/
- local/ - local/
- db.sh - db.sh
- path.sh - path.sh
- cmd.sh - cmd.sh
- run.sh - run.sh
- asr.sh - tts.sh
上記からわかるように、ASRとTTSレシピの間でディレクトリ構造は共通となっており、テンプレートスクリプトであるasr.shとtts.shのみが異なります。
ここでは、いくつかの重要なファイルについて概説します。その他のファイルに関しては、ESPnet2 tutorialを参照してください。
cmd.sh: レシピ内の各処理をどのように実行するかを設定するファイル。テンプレートスクリプトによって呼び出されます。ファイル内のcmd_backendを変更することで、レシピ内の各処理をSlurmなどのジョブスケジューラを通して実行することが可能になります。デフォルトではcmd_backend=localとなっており、レシピを実行したローカルマシンで処理を行います。ジョブスケジューラを利用しない場合は編集せずにそのまま利用します。ジョブスケジューラとの連携の詳細に関しては、ジョブスケジューラの利用を参照してください。path.sh: 環境変数の管理を行うファイル。テンプレートスクリプトによって呼び出される。このファイルを読み込むことで、インストールした各種ツールへのパスが通り、環境構築の際に作成したPython環境がアクティベートされる。レシピの実行の際に設定しておきたい環境変数がある場合は、このファイルに追記を行うと良いです。db.sh: 各種コーパスのパスを設定するファイル。主に、自動的にダウンロードを行うことができない有償のコーパスを利用したレシピを実行する際に編集する必要があります。asr.sh(tts.sh): ASR(もしくはTTS)モデル構築のためのテンプレートスクリプト。モデルの構築に必要な複数のステージで構成されたシェルスクリプト。run.shによって呼び出されます。local/data.sh: 学習セット、検証セット、及び評価セットに対応するKaldi方式のデータディレクトリ(データディレクトリの構造を参照)を生成するシェルスクリプト。テンプレートスクリプトによって呼び出されます。レシピごとに固有のスクリプトであり、新しいレシピを追加する際には、基本的にこのスクリプトを作成することが主な作業となります。conf/: ジョブスケジューラとの連携のための設定ファイル(*.conf)や、ネットワークの学習及び推論のハイパーパラメータ設定ファイル(*.yaml)を含むディレクトリ。このディレクトリ内の設定ファイル(*.yaml)を編集し、それらをテンプレートスクリプトのオプションとして渡すことで様々なネットワークを学習することできるようになります。run.sh: テンプレートスクリプトのオプションを指定し実行するためのシェルスクリプト。レシピごとに固有のファイル。このファイルを実行することで、レシピを一通り実行することが可能となります。
このディレクトリ構造は全レシピで共通であり、実行ファイルであるrun.sh、データ整形のためのlocal/data.sh、そしてネットワークの設定ファイル(*.yaml)の内容のみがレシピごとが異なります。
データディレクトリの構造
ここでは、local/data.shによって作成されるKaldi方式のデータディレクトリの構造を概説します。データディレクトリは、学習セット、検証セット、そして評価セットごとに用意されます。複数の評価セットが存在する場合は、各評価セットに対応するデータディレクトリがそれぞれ作成されます。
各データディレクトリに含まれるファイルは以下の4つ、もしくは5つです。
-
wav.scp音声IDと対応する音声ファイルのパスを示したファイル。下記に例を示します。utt_id_1 /path/to/utt_id_1.wav utt_id_2 /path/to/utt_id_2.wav utt_id_3 /path/to/utt_id_3.wav各行は音声IDでソートされ、音声IDはユニークである必要があります。IDの命名規則は自由ですが、
<話者名>_<音声ファイル名>とすることが多いです。後述のsegmentsファイルがデータディレクトリ内に存在しない場合、音声IDが発話IDとして利用されます。音声ファイルのパスの部分は、任意のコマンドのパイプに置き換えることも可能です。以下に、
soxコマンドによってサンプリングレートを変換する際の例を示します。utt_id_1 sox /path/to/utt_id_1.wav -t wav - rate 24000 | utt_id_2 sox /path/to/utt_id_2.wav -t wav - rate 24000 | utt_id_3 sox /path/to/utt_id_3.wav -t wav - rate 24000 |コマンドを記述した場合、このファイルを読み込む際に自動的にコマンドが実行され、その出力読み込むことが可能です。可読性は落ちますが、中間ファイルを生成したくない場合に便利な記法です。
-
text: 発話IDとその発話IDの音声の発話内容を記したファイル。下記に例を示します。utt_id_1 飛ぶ自由を得ることは utt_id_2 人類の夢であった utt_id_3 55歳だって嬉しいときは嬉しいのだ各行は発話IDでソートされている必要があります。TTSでは、入力として音素や読みを利用することが多いですが、ESPnet2では生のテキストから音素への変換は学習もしくは推論時に逐次的に行われるため、データディレクトリの準備の段階では生のテキストを利用してこのファイルを作成すれば良いです。
-
utt2spk: 発話IDとその発話IDの音声の話者IDを記したファイル。下記に例を示します。utt_id_1 spk_1 utt_id_2 spk_1 utt_id_3 spk_2ESPnetでは基本的に話者情報を利用しないので、話者情報が存在しない場合はダミーの話者IDを利用すれば良いです(例:
utt_id_1 dummy)。 -
spk2utt: 話者IDとその話者の発話IDを並べたファイル。下記に例を示します。spk_1 utt_id_1 utt_id_2 spk_2 utt_id_3このファイルは
utt2spkファイルから自動的に生成することが可能なので、自分で作成する必要はありません。 -
segments(Optional): 発話ID、音声ID、開始 [sec]、終端 [sec]を記したファイル。wav.scp内の各発話をさらに細かく分割する場合に利用します。下記に例を示します。utt_id_1_000000_001000 utt_id_1 0.0 10.0 utt_id_1_001000_001500 utt_id_1 10.0 15.0各行は発話IDソートされ、発話IDはユニークである必要があります。このファイルが存在する場合、
text、utt2spk、そしてspk2utt内の発話IDが、wav.scpの音声IDではなく、segmentsファイルの発話IDに対応するようになります。 このため、segments、text、そしてutt2spkの行数は必ず一致する必要があります。segmentsは、非常に長い講演音声などを中間ファイルを生成することなく処理したい場合に利用することが多いです。また、TTSモデルを学習する際に、始端と終端のサイレンスを取り除きたい場合にも利用することができます。この場合、音声IDと発話IDが1対1対応となるため、発話IDと音声IDは同じものを利用することができます。utt_id_1 utt_id_1 1.5 4.0 utt_id_2 utt_id_2 3.1 12.0 utt_id_3 utt_id_3 2.1 9.0
ASRレシピの流れ
ここでは、ASRレシピの流れを説明します。ASRレシピのテンプレートスクリプト(asr.sh)は全14ステージで構成されています。
以下では、各ステージで行われる処理を簡単に概説します。
-
Stage 1: 学習セット、検証セット、そして評価セットに対応するデータディレクトリを生成するステージ。
local/data.shが呼び出されます。 -
Stage 2(Optional): 話速変化に基づくデータ拡張を実施するステージ。
--speed_purturb_factorsオプションを指定した場合のみ実行されます。Stage 1で作成された学習セットのデータディレクトリ内のwav.scpをsoxコマンドを用いて拡張します。 -
Stage 3: 特徴量抽出を行うステージ。
--feats_typeオプションに応じて処理が異なります。デフォルトはfeats_type=rawであり、特徴量抽出の代わりにwav.scpの整形のみが行われます。feats_type=raw以外を利用する場合は、Kaldiの特徴量抽出を利用します。この場合、Kaldiのコンパイルが必要となります。 -
Stage 4: 発話のフィルタリングを行うステージ。学習セットと検証セットの中の最短しきい値以下の発話と最長しきい値以上の長さの発話を取り除きます。最短及び最長しきい値は
--min_wav_duration及び--max_wav_durationオプションでそれぞれ指定することができます。 -
Stage 5: トークンリスト(辞書)を作成するステージ。
--token_typeオプションに応じて、利用するトークンのタイプが異なります。ASRではtoken_type=charもしくはtoken_type=bpeが利用可能です。token_type=bpeの場合、SentencePieceによるサブワードへの分割が行われます。 -
Stage 6(Optional): 言語モデル学習のための統計量を算出するステージ。動的にバッチサイズを変更するための各データのシェイプ情報(系列長及び次元数)を取得します。言語モデルの利用をしない場合、
--use_lmオプションをuse_lm=falseにすることでStage 6から8までをスキップすることができます。 -
Stage 7(Optional): 言語モデルの学習を行うステージ。
--lm_config及び--lm_argsオプションに応じて言語モデルの学習を行います。 -
Stage 8(Optional): 学習した言語モデルのパープレキシティ(PPL)を計算するステージ。簡易的に言語モデルの評価を実施します。
-
Stage 9: ASRモデルの学習のための統計量を算出するステージ。動的にバッチサイズを変更するためのデータのシェイプ情報(系列長及び次元数)と、特徴量の正規化を行うための学習データ全体の統計量(平均及び分散)を計算します。
-
Stage 10: ASRモデルの学習を行うステージ。
--asr_config及び--asr_argsオプションに応じてASRモデルの学習を行います。 -
Stage 11: 学習したモデルを利用してデコーディングを行うステージ。
--inference_config及び--inference_argsオプションに応じて、学習した言語モデルとASRモデルを用いた推論を行います。 -
Stage 12: デコードされた結果の評価を行うステージ。Character Error Rate(CER)及びWord Error Rate(WER)を算出します。
-
Stage 13-14(Optional): 学習済みのモデルのパッキング及びZenodoへのアップロードを行うステージ。利用するには、Zenodoにユーザー登録を行い、トークンを発行する必要があります。詳細に関してはESPnet Model Zooを参照してください。
全ての利用可能なオプションはasr.sh --helpで参照することができます。
$ cd espnet/egs2/TEMPLATE/asr1
$ ./asr.sh --help
2020-09-14T15:38:49(asr.sh:208:main) ./asr.sh --help
Usage: ./asr.sh --train-set <train_set_name> --valid-set <valid_set_name> --test_sets <test_set_names> --srctexts <srctexts>
Options:
# General configuration
--stage # Processes starts from the specified stage(default="1").
--stop_stage # Processes is stopped at the specified stage(default="10000").
--skip_data_prep # Skip data preparation stages(default="false").
--skip_train # Skip training stages(default="false").
--skip_eval # Skip decoding and evaluation stages(default="false").
--skip_upload # Skip packing and uploading stages(default="true").
--ngpu # The number of gpus("0" uses cpu, otherwise use gpu, default="1").
--num_nodes # The number of nodes(default="1").
--nj # The number of parallel jobs(default="32").
--inference_nj # The number of parallel jobs in decoding(default="32").
--gpu_inference # Whether to perform gpu decoding(default="false").
--dumpdir # Directory to dump features(default="dump").
--expdir # Directory to save experiments(default="exp").
--python # Specify python to execute espnet commands(default="python3").
# Data preparation related
--local_data_opts # The options given to local/data.sh(default="").
# Speed perturbation related
--speed_perturb_factors # speed perturbation factors, e.g. "0.9 1.0 1.1"(separated by space, default="").
# Feature extraction related
--feats_type # Feature type(raw, fbank_pitch or extracted, default="raw").
--audio_format # Audio format(only in feats_type=raw, default="flac").
--fs # Sampling rate(default="16k").
--min_wav_duration # Minimum duration in second(default="0.1").
--max_wav_duration # Maximum duration in second(default="20").
# Tokenization related
--token_type # Tokenization type(char or bpe, default="bpe").
--nbpe # The number of BPE vocabulary(default="30").
--bpemode # Mode of BPE(unigram or bpe, default="unigram").
--oov # Out of vocabulary symbol(default="<unk>").
--blank # CTC blank symbol(default="<blank>").
--sos_eos # sos and eos symbole(default="<sos/eos>").
--bpe_input_sentence_size # Size of input sentence for BPE(default="100000000").
--bpe_nlsyms # Non-linguistic symbol list for sentencepiece, separated by a comma.(default="").
--bpe_char_cover # Character coverage when modeling BPE(default="1.0").
# Language model related
--lm_tag # Suffix to the result dir for language model training(default="").
--lm_exp # Specify the direcotry path for LM experiment.
# If this option is specified, lm_tag is ignored(default="").
--lm_config # Config for language model training(default="").
--lm_args # Arguments for language model training(default="").
# e.g., --lm_args "--max_epoch 10"
# Note that it will overwrite args in lm config.
--use_word_lm # Whether to use word language model(default="false").
--word_vocab_size # Size of word vocabulary(default="10000").
--num_splits_lm # Number of splitting for lm corpus(default="1").
# ASR model related
--asr_tag # Suffix to the result dir for asr model training(default="").
--asr_exp # Specify the direcotry path for ASR experiment.
# If this option is specified, asr_tag is ignored(default="").
--asr_config # Config for asr model training(default="").
--asr_args # Arguments for asr model training(default="").
# e.g., --asr_args "--max_epoch 10"
# Note that it will overwrite args in asr config.
--feats_normalize # Normalizaton layer type(default="global_mvn").
--num_splits_asr # Number of splitting for lm corpus (default="1").
# Decoding related
--inference_tag # Suffix to the result dir for decoding(default="").
--inference_config # Config for decoding(default="").
--inference_args # Arguments for decoding(default="").
# e.g., --inference_args "--lm_weight 0.1"
# Note that it will overwrite args in inference config.
--inference_lm # Language modle path for decoding(default="valid.loss.ave.pth").
--inference_asr_model # ASR model path for decoding(default="valid.acc.ave.pth").
--download_model # Download a model from Model Zoo and use it for decoding(default="").
# [Task dependent] Set the datadir name created by local/data.sh
--train_set # Name of training set(required).
--valid_set # Name of validation set used for monitoring/tuning network training(required).
--test_sets # Names of test sets.
# Multiple items(e.g., both dev and eval sets) can be specified(required).
--srctexts # Used for the training of BPE and LM and the creation of a vocabulary list(required).
--lm_dev_text # Text file path of language model development set(default="").
--lm_test_text # Text file path of language model evaluation set(default="").
--nlsyms_txt # Non-linguistic symbol list if existing(default="none").
--cleaner # Text cleaner(default="none").
--g2p # g2p method(default="none").
--lang # The language type of corpus(default=noinfo).
--asr_speech_fold_length # fold_length for speech data during ASR training(default="800").
--asr_text_fold_length # fold_length for text data during ASR training(default="150").
--lm_fold_length # fold_length for LM training(default="150").
ASRのレシピの実行
ここでは、実際のASRレシピの実行手順を紹介します。JSUTコーパスを用いたASRレシピをサンプルとして利用します。
まず、レシピのディレクトリに移動します。
$ cd espnet/egs2/jsut/asr1
レシピ内の全てのスクリプトは、レシピディレクトリのルート(egs2/<corpus_name>/<task>)から実行されることを想定しています。そのため、レシピを実行する際は、常にレシピディレクトリのルートをワーキングディレクトリとすることに注意してください。
次に、cmd.sh及びdb.shの編集を行います。
$ vim cmd.sh
$ vim db.sh
ジョブスケジューラと連携してレシピを実行する場合、cmd.shのcmd_backendを変更します(デフォルトはcmd_backend=local)。コーパスがダウンロードされる場所を変更する場合、db.shのJSUTを変更します(デフォルトはJSUT=downloads)。いずれもデフォルトの設定を利用する場合、編集を行う必要はありません。
編集完了後、run.shを実行します。
$ ./run.sh
これにより、全てのステージが順次実行され、実験は完了となります。デフォルトでは、RNNベースのJoint CTC-Attentionモデルが学習されます。
レシピの実行完了後、以下に示すディレクトリがワーキングディレクトリ内に追加されます。
#########################
# Stage 1-5で作成 #
#########################
# ダウンロードされたコーパス
- downloads/
├ jsut-lab/
└ jsut_ver1.1/
# データディレクトリ
- data/
├ dev/ # 検証セット
├ eval1/ # 評価セット
├ token_list/ # トークンリスト(辞書)
└ tr_no_dev/ # 学習セット
# 特徴量ディレクトリ
- dump/
└ raw/
├ dev/ # 検証セット
├ eval1/ # 評価セット
├ tr_no_dev/ # 学習セット
└ srctexts # 言語モデル学習用テキスト
#(辞書作成用兼)
#########################
# Stage 6以降で作成 #
#########################
# 実験ディレクトリ
- exp/
├ asr_stats_raw/
│ ├ train/ # 学習セットASR統計量
│ └ valid/ # 検証セットASR統計量
├ asr_train_asr_rnn_raw_char/
│ ├ att_ws/ # Attentionプロット
│ ├ decode_*/ # デコーディング結果
│ ├ tensorboard/ # Tensorboardログ
│ ├ images/ # 学習曲線プロット
│ ├ README.md # 評価結果のサマリー
│ ├ train.log # 学習ログ
│ ├ *.pth # モデルパラメータ
│ └ checkpoint.pth # モデルパラメータ(Optimizer等を含む)
├ lm_stats/
│ ├ train/ # 学習セットLM統計量
│ └ valid/ # 検証セットLM統計量
└ lm_train_lm_char/
├ perplexity_*/ # PPL評価結果
├ tensorboard/ # Tensorboardログ
├ images/ # 学習曲線プロット
├ train.log # 学習ログ
├ *.pth # モデルパラメータ
└ checkpoint.pth # モデルパラメータ(Optimizer等を含む)
実験ディレクトリ内のimages/及びtensorboardは逐次更新されていくので、実験の様子をモニタリングするのに便利です。以下にimages/に生成される学習曲線の例を示します。
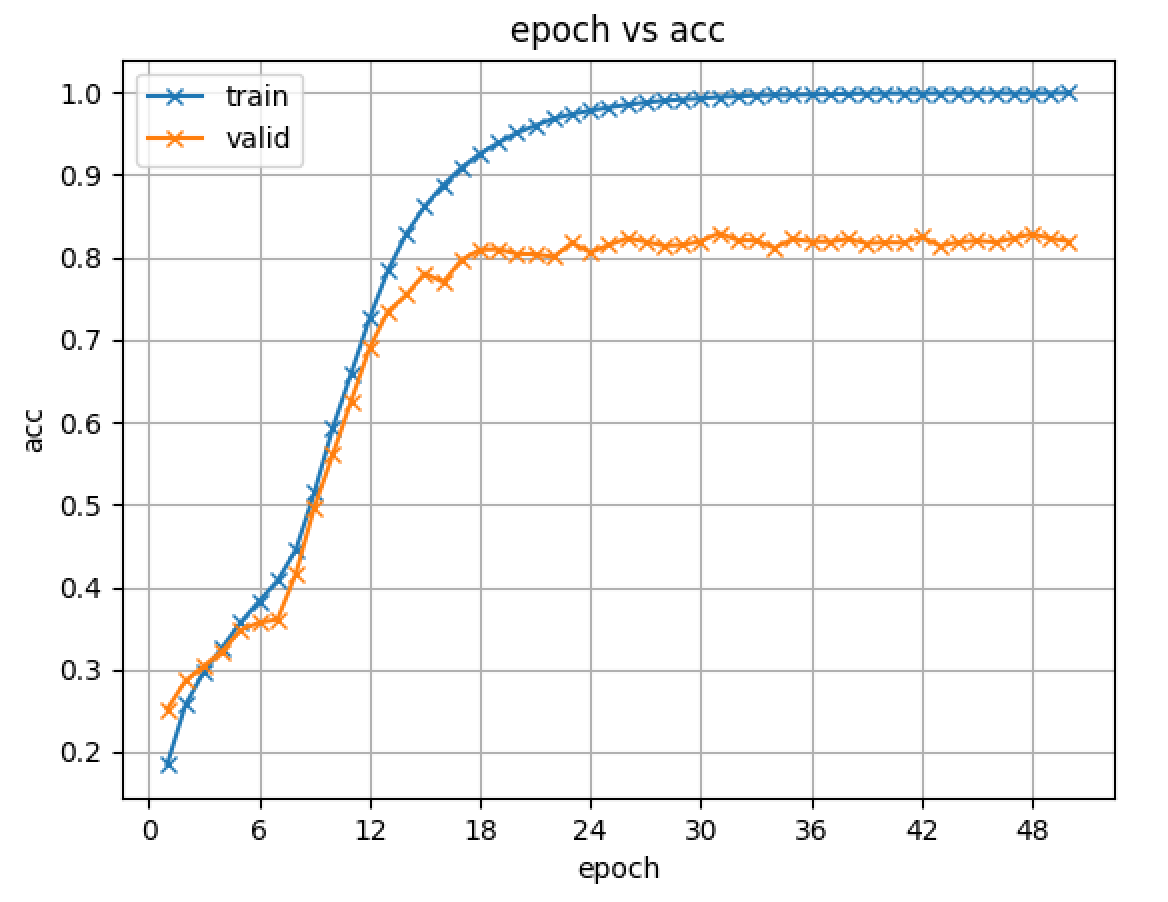
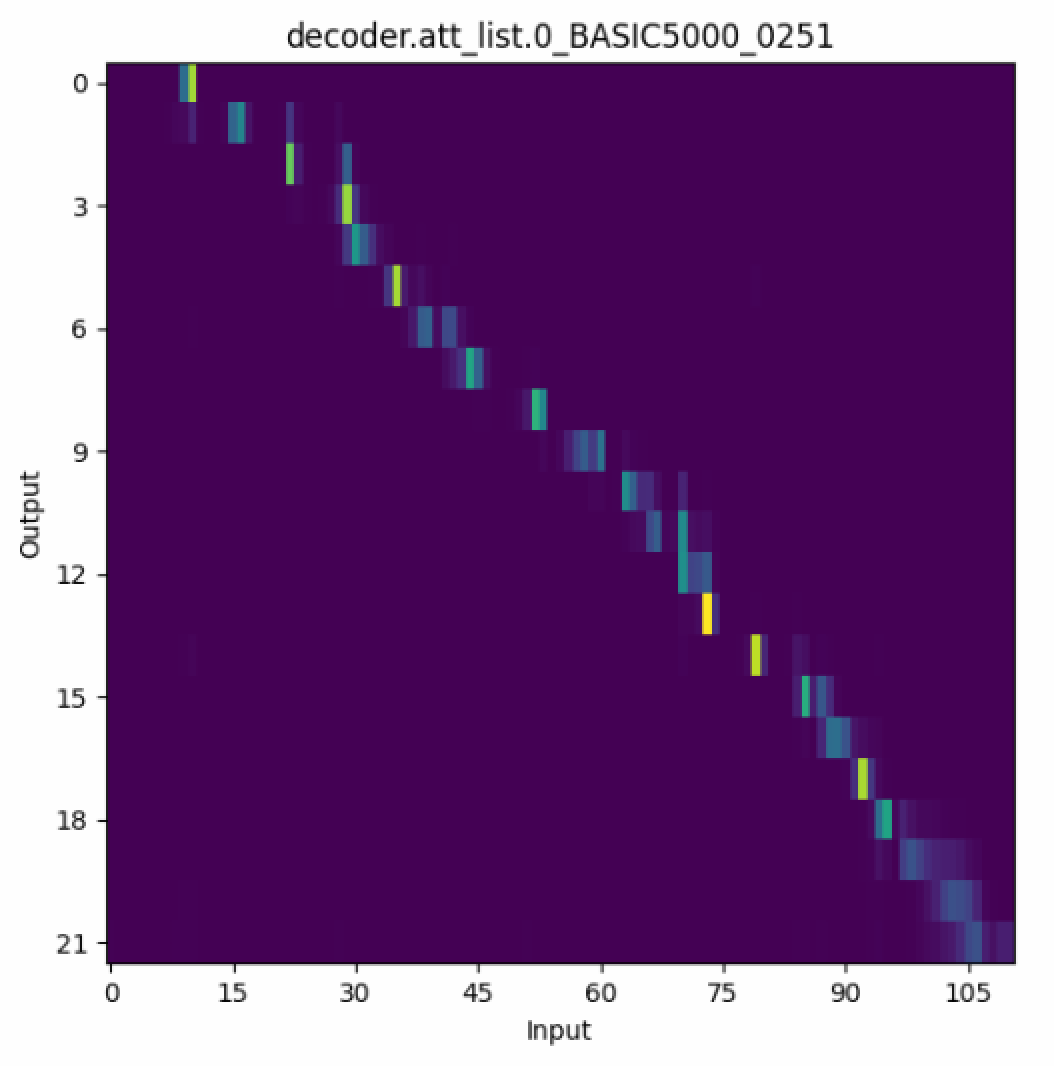
同様に、att_wsにはエポックごとのAttentionのプロットが保存されています。Seq2SeqモデルではAttentionが対角になることが非常に重要であるため、学習曲線と合わせてモニタリングすることをおすすめします。以下にatt_ws/に生成されるプロットの例を示します。
run.shを実行することで一通り実験は完了しますが、初心者の場合、開始及び終了ステージを指定するオプションである--stageと--stop-stageを利用して、それぞれのステージを順番に実行することをおすすめします。
# stage 1のみを実行
$ ./run.sh --stage 1 --stop-stage 1
# stage 2のみを実行
$ ./run.sh --stage 2 --stop-stage 2
これにより、各ステージでどのようなファイルが生成されるのかを確認しながら実験を進めることができます。
ここからは、レシピをより実践的に利用するためのオプションをいくつか概説します。マルチGPUによる学習行う場合、--ngpuオプションを利用します。
$ ./run.sh --ngpu 3
ローカルで実行する際(cmd_backend=local)に、利用するGPUを指定する場合、環境変数CUDA_VISIBLE_DEVICESを指定します。
Slurm等のジョブスケジューラと連携している際には、自動的にGPUが割り当てられるため、指定する必要はありません。
$ CUDA_VISIBLE_DEVICES=0,1,2 ./run.sh --ngpu 3
Slurm等のジョブスケジューラと連携している際には、マルチノード学習も可能です。 4つのノードを利用し、それぞれのノードで4つのGPUを利用する場合の例を示します($4\times4=16$ GPUs)。
$ ./run.sh --ngpu 4 --num_nodes 4
学習するASRモデルを変更するには、\code{–asr_config}に渡すコンフィグファイルを変更します。
$ ./run.sh --asr_config conf/train_asr_transformer.yaml
もし、既に一度他のモデルを学習し終わっている場合には、最初のステージをスキップしてASRモデル学習のステージから始めることもできます。
$ ./run.sh --stage 10 --asr_config conf/train_asr_transformer.yaml
モデルのハイパーパラメータを変更して学習を行うには、逐次コンフィグファイル(*.yaml)をコピー・編集しても良いですが、一部のパラメータのみを変更したい場合は--asr_argsオプションを利用するのが便利です。以下に、指定したコンフィグ(*.yaml)内のバッチサイズを上書きして利用する例を示します。
$ ./run.sh --stage 10 \
--asr_config conf/train_asr_rnn.yaml \
--asr_args "--batch_size 64"
複数のオプションを変更したり、Dict型のオプションを変更することも可能です。以下に、バッチサイズとOptimizerの学習率を変更する例を示します。
$ ./run.sh --stage 10 \
--asr_config conf/train_asr_rnn.yaml \
--asr_args "--batch_size 64 --optim_conf lr=0.1"
--asr_argsオプションを指定した場合、自動的に保存されるディレクトリの名前も指定したオプションに応じて更新されます。そのため、モデルが上書きされる心配をする必要はありません。また、これにより、forループを利用した簡易的なハイパーパラメータの探索も可能です。
また、--asr_tagオプションを利用することでモデルディレクトリの名前を明示的に決めることも可能です。
$ ./run.sh --stage 10 \
--asr_config conf/train_asr_rnn.yaml \
--asr_args "--batch_size 64 --optim_conf lr=0.1" \
--asr_tag "train_rnn_batchs_size_64_lr_0.1"
言語モデルや推論のコンフィグの変更も全く同様です。言語モデルのコンフィグの変更の場合、--lm_configオプションと--lm_argsオプションが、推論のコンフィグの変更の場合、--inference_configオプションと--inference_argsオプションがそれぞれコンフィグファイルの指定と上書きに対応します。
コンフィグファイル(*.yaml)で指定可能なオプションの一覧を表示するには以下のコマンドを利用します。
# Python環境のアクティベート
$ . ./path.sh
# Helpメッセージの表示
$ python3 -m espnet2.bin.lm_train --help
$ python3 -m espnet2.bin.asr_train --help
$ python3 -m espnet2.bin.lm_inference --help
$ python3 -m espnet2.bin.asr_inference --help
# デフォルトコンフィグを表示
$ python3 -m espnet2.bin.lm_train --print_config
$ python3 -m espnet2.bin.asr_train --print_config
# 与えられたコンフィグをファイルを反映したコンフィグを表示
$ python3 -m espnet2.bin.lm_train --print_config --config conf/train_lm.yaml
$ python3 -m espnet2.bin.asr_train --print_config --config conf/train_asr_transformer.yaml
より詳細に関しては、コンフィグの変更を参照してください。
TTSレシピの流れ
ここでは、TTSレシピの流れについて概説します。TTSのテンプレートスクリプト(tts.sh)は以下の9ステージで構成されています。
- Stage 1: データディレクトリを生成するステージ。ASRレシピのStage 1と同一です。
- Stage 2: 特徴量抽出を行うステージ。ASRレシピのStage 3と同一です。
- Stage 3: 発話のフィルタリングを行うステージ。 ASRレシピのStage 4と同一です。
- Stage 4: トークンリスト(辞書)を作成するステージ。
--token_typeオプションに応じて、利用するトークンのタイプが異なります。TTSではtoken_type=charもしくはtoken_type=phnが利用可能です。token_type=phnの場合、--g2pオプションで指定されたGrapheme to Phoneme(G2P)モジュールによって音素へと変換されます。日本語の場合、g2p=pyopenjtalkを指定することでOpenJTalkのテキストフロントエンド部を利用した音素への変換を行うことができます。また、--cleanerオプションでテキストのクリーニングを行うモジュールを指定することもできます。 - Stage 5: TTSモデル学習のための統計量を計算するステージ。動的にバッチサイズを変更するためのデータのシェイプ情報(系列長及び次元数)と、学習データ全体での音響特徴量の統計量(平均及び分散)を計算します。
- Stage 6: TTSモデルの学習を行うステージ。
--train_config及び--train_argsオプションに応じてTTSモデルの学習を行います。 - Stage 7: 学習したTTSモデルを利用してデコーディングを行うステージ。
--inference_config及び--inference_argsオプションに応じて推論を行います。 - Stage 8-9(Optional): 学習済みのモデルのパッキング及びZenodoへのアップロードを行うステージ。ASRのStage 13-14と同一です。
全ての利用可能なオプションはtts.sh --helpで参照することができます。
$ cd espnet/egs2/TEMPLATE/tts1
$ ./tts.sh --help
2020-09-14T15:59:21(tts.sh:187:main) ./tts.sh --help
Usage: ./tts.sh --train-set "<train_set_name>" --valid-set "<valid_set_name>" --test_sets "<test_set_names>" --srctexts "<srctexts>"
Options:
# General configuration
--stage # Processes starts from the specified stage(default="1").
--stop_stage # Processes is stopped at the specified stage(default="10000").
--skip_data_prep # Skip data preparation stages(default="false").
--skip_train # Skip training stages(default="false").
--skip_eval # Skip decoding and evaluation stages(default="false").
--skip_upload # Skip packing and uploading stages(default="true").
--ngpu # The number of gpus("0" uses cpu, otherwise use gpu, default="1").
--num_nodes # The number of nodes(default="1").
--nj # The number of parallel jobs(default="32").
--inference_nj # The number of parallel jobs in decoding(default="32").
--gpu_inference # Whether to perform gpu decoding(default="false").
--dumpdir # Directory to dump features(default="dump").
--expdir # Directory to save experiments(default="exp").
--python # Specify python to execute espnet commands(default="python3").
# Data prep related
--local_data_opts # Options to be passed to local/data.sh(default="").
# Feature extraction related
--feats_type # Feature type(fbank or stft or raw, default="raw").
--audio_format # Audio format(only in feats_type=raw, default="flac").
--min_wav_duration # Minimum duration in second(default="0.1").
--max_wav_duration # Maximum duration in second(default="20").
--fs # Sampling rate(default="16000").
--fmax # Maximum frequency of Mel basis(default="7600").
--fmin # Minimum frequency of Mel basis(default="80").
--n_mels # The number of mel basis(default="80").
--n_fft # The number of fft points(default="1024").
--n_shift # The number of shift points(default="256").
--win_length # Window length(default="null").
--f0min # Maximum f0 for pitch extraction(default="80").
--f0max # Minimum f0 for pitch extraction(default="400").
--oov # Out of vocabrary symbol(default="<unk>").
--blank # CTC blank symbol(default="<blank>").
--sos_eos # sos and eos symbole(default="<sos/eos>").
# Training related
--train_config # Config for training(default="").
--train_args # Arguments for training(default="").
# e.g., --train_args "--max_epoch 1"
# Note that it will overwrite args in train config.
--tag # Suffix for training directory(default="").
--tts_exp # Specify the direcotry path for experiment.
# If this option is specified, tag is ignored(default="").
--tts_stats_dir # Specify the direcotry path for statistics.
# If empty, automatically decided(default="").
--num_splits # Number of splitting for tts corpus(default="1").
--write_collected_feats # Whether to dump features in statistics collection(default="false").
# Decoding related
--inference_config # Config for decoding(default="").
--inference_args # Arguments for decoding,(default="").
# e.g., --inference_args "--threshold 0.75"
# Note that it will overwrite args in inference config.
--inference_tag # Suffix for decoding directory(default="").
--inference_model # Model path for decoding(default=train.loss.ave.pth).
--griffin_lim_iters # The number of iterations of Griffin-Lim(default=4).
--download_model # Download a model from Model Zoo and use it for decoding(default="").
# [Task dependent] Set the datadir name created by local/data.sh.
--train_set # Name of training set(required).
--valid_set # Name of validation set used for monitoring/tuning network training(required).
--test_sets # Names of test sets(required).
# Note that multiple items(e.g., both dev and eval sets) can be specified.
--srctexts # Texts to create token list(required).
# Note that multiple items can be specified.
--nlsyms_txt # Non-linguistic symbol list(default="none").
--token_type # Transcription type(default="phn").
--cleaner # Text cleaner(default="tacotron").
--g2p # g2p method(default="g2p_en").
--lang # The language type of corpus(default="noinfo").
--text_fold_length # Fold length for text data(default="150").
--speech_fold_length # Fold length for speech data(default="800").
TTSレシピの実行
ここでは、実際のASRレシピの実行手順を紹介します。JSUTコーパスを用いたTTSレシピをサンプルとして利用します。基本的な実行方法はASRレシピの場合と全く同様です。
レシピディレクトリに移動してrun.shを実行します。
$ cd espnet/egs2/jsut/tts1
$ ./run.sh
ASRの場合と同様に、最初は各ステージを逐次的に実行して確認することをおすすめします。
# Stage 1のみを実行
$ ./run.sh --stage 1 --stop-stage 1
# Stage 2のみを実行
$ ./run.sh --stage 2 --stop-stage 2
デフォルトでは、音素を入力としたTacotron2が学習されます。
レシピの実行完了後、以下に示すディレクトリがワーキングディレクトリ内に追加されます。
#########################
# Stage 1-4で作成 #
#########################
# ダウンロードされたコーパス
- downloads/
├ jsut-lab/
└ jsut_ver1.1/
# データディレクトリ
- data/
├ dev/ # 検証セット
├ eval1/ # 評価セット
├ token_list/ # トークンリスト(辞書)
└ tr_no_dev/ # 学習セット
# 特徴量ディレクトリ
- dump/
└ raw/
├ dev/ # 検証セット
├ eval1/ # 評価セット
├ tr_no_dev/ # 学習セット
└ srctexts # 辞書作成用テキスト
#########################
# Stage 5以降で作成 #
#########################
# 実験ディレクトリ
- exp/
├ tts_stats_*/
│ ├ train/ # 学習セット統計量
│ └ valid/ # 検証セット統計量
└ tts_train_*/
├ att_ws/ # Attentionプロット
├ decode_*/ # デコーディング結果
├ tensorboard/ # Tensorboardログ
├ images/ # 学習曲線プロット
├ train.log # 学習ログ
├ *.pth # モデルパラメータ
└ checkpoint.pth # モデルパラメータ(Optimizer等を含む)
デコーディング結果の中身は以下の通りです。
- exp/tts_train_*/decode_*/
├ dev/ # 検証セットのデコード結果
└ eval1/ # 評価セットのデコード結果
├ att_ws/ # Attentionプロット
├ probs/ # 生成打切確率プロット
├ denorm/ # 逆正規化後生成特徴量
├ norm/ # 正規化後生成特徴量
├ wav/ # 生成音声
├ durations # 各音素の継続長
├ feats_type # 特徴量の種類
├ focus_rates # フォーカスレート
└ speech_shape # 生成特徴量のシェイプ情報
ここで、音声はGriffin-Limによって生成され、継続長及びフォーカスレートは生成時のAttentionから計算される指標です。
ユーザーは、生成された特徴量ファイルを利用することで、任意のニューラルボコーダと組み合わせることが可能できます。より詳細に関しては、ParallelWaveGANを参照してください。
また、生成時のAttention(att_ws/*.png)や生成打ち切り確率のプロット(probs/*.png)を観察することで、生成がうまく行っているかを分析できます。以下に二つのプロットの例を示します。
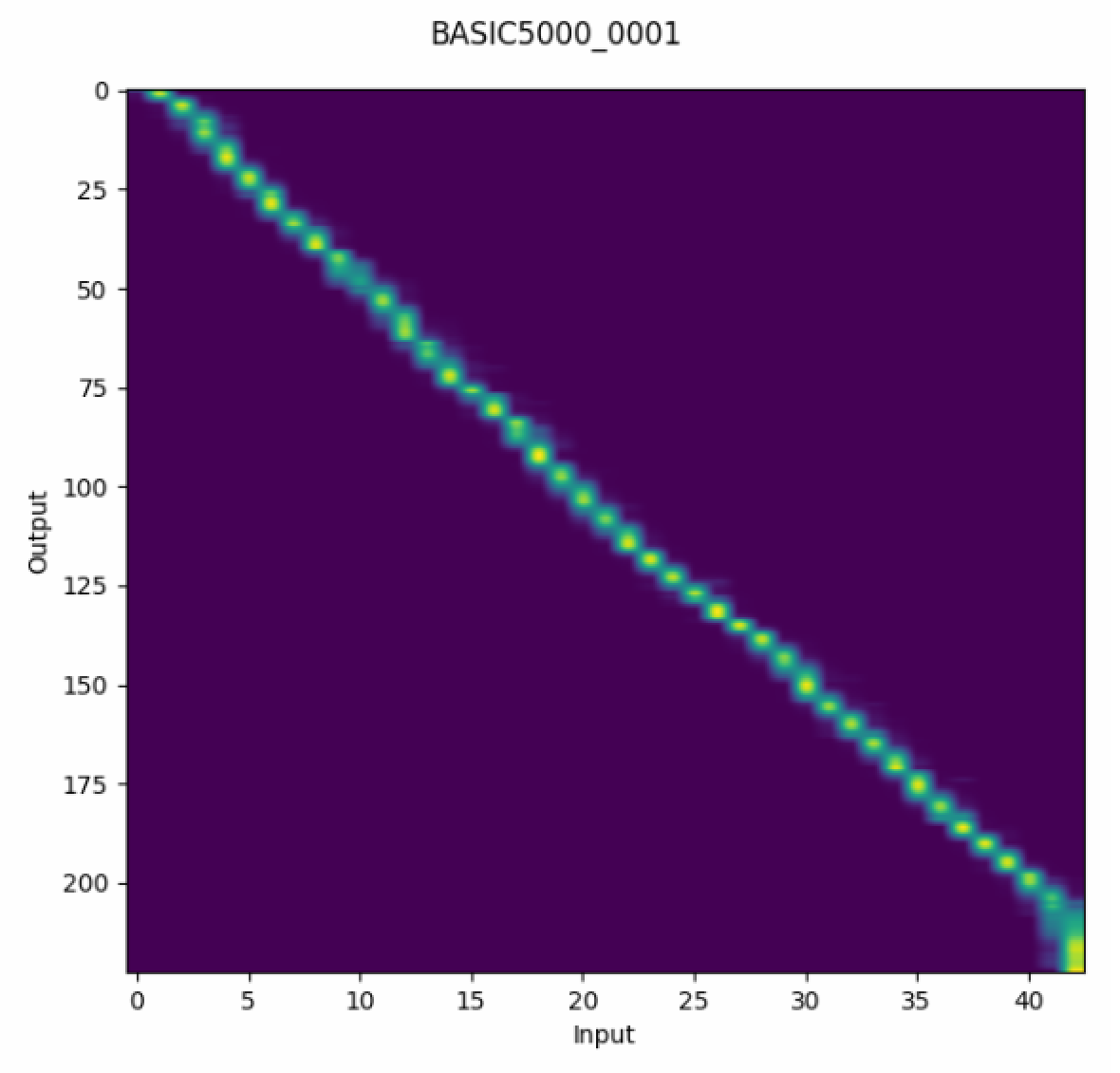
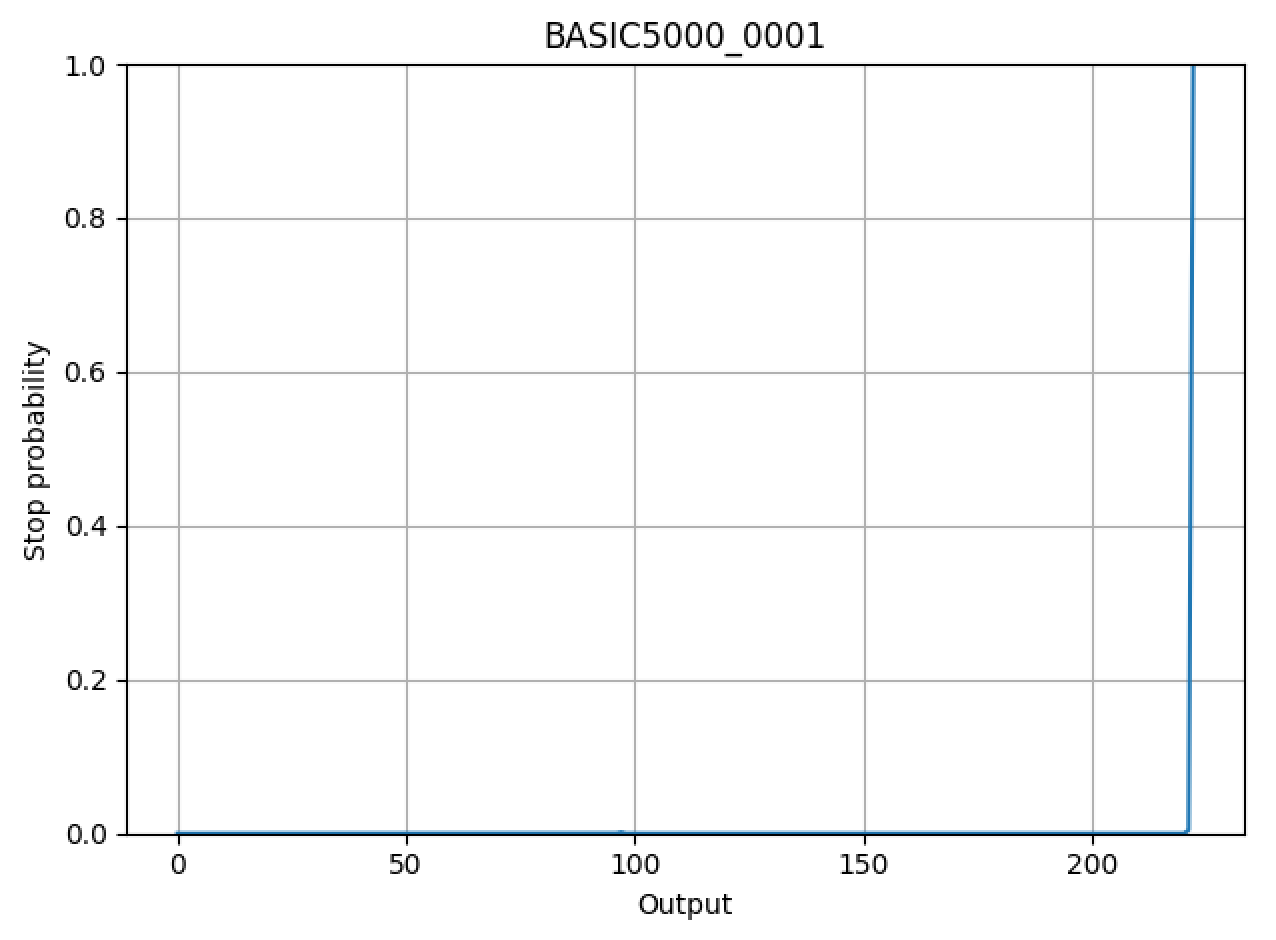
レシピの実行の際のオプションはASRの場合と全く同様ですが、コンフィグファイル(*.yaml)で指定可能なオプションを参照する際は以下のコマンドを実行します。
# Python環境のアクティベート
$ . ./path.sh
# Helpメッセージの表示
$ python3 -m espnet2.bin.tts_train --help
$ python3 -m espnet2.bin.tts_inference --help
# デフォルトコンフィグを表示
$ python3 -m espnet2.bin.tts_train --print_config
# 与えられたコンフィグをファイルを反映したコンフィグを表示
$ python3 -m espnet2.bin.tts_train --print_config --config conf/train.yaml
その他のTTSレシピに関するよくある質問はコチラにまとめてあるので、本記事と合わせて参照してください。
非自己回帰型モデルの学習
TTSレシピでは、自己回帰モデル(Tacotron2、Transformer-TTS)だけでなく、非自己回帰モデル(FastSpeech、FastSpeech2)の学習もサポートされています。非自己回帰モデルの学習には、教師モデルから生成される入力トークンの継続長情報が必要となるため、学習済みの教師モデルを利用した追加の手順が必要となります。
まず、知識蒸留を利用したFastSpeechの学習手順を示します。知識蒸留を利用した学習の場合、FastSpeechのターゲットとなる音響特徴量は教師モデルが生成した音響特徴量となり、Groundtruthの音響特徴量は利用しません。このため、--tts_expオプションで学習済みモデルのディレクトリを指定し、学習データを含む全データをデコードします。
$ ./run.sh --stage 7 \
--tts_exp exp/<teacher_model_dir> \
--test_sets "tr_no_dev dev eval1"
これにより、exp/<teacher_model_dir>/decode_train.loss.aveディレクトリに全データのデコード結果が保存されます。--teacher_dumpdirオプションでこのディレクトリを指定し、FastSpeechのコンフィグを使ってモデル学習のステージからレシピを実行します。
$ ./run.sh --stage 6 \
--teacher_dumpdir exp/<teacher_model_dir>/decode_train.loss.ave \
--train_config conf/tuning/train_fastspeech.yaml
以上で、FastSpeechの学習は完了となります。
次に、FastSpeech2の学習手順を示します。FastSpeech2では、FastSpeechと異なり、ターゲットとしてGroundtruthの音響特徴量を利用します。そのため、デコードの際にTeacher-Forcingを有効にし、Groundtruthの音響特徴量に対応した継続長(durations)を生成します。
$ ./run.sh --stage 7 \
--tts_exp exp/<teacher_model_dir> \
--test_sets "tr_no_dev dev eval1" \
--inference_args "--use_teacher_forcing true"
これにより、Teacher-Forcingを利用した全データのデコード結果が保存されます。FastSpeech2では、ピッチとエナジーの2つの追加の特徴量が必要となるため、ネットワークの学習ではなく、統計量の計算のステージからレシピを実行します。
$ ./run.sh --stage 5 \
--write_collected_feats true \
--teacher_dumpdir exp/<teacher_model_dir>/decode_use_teacher_forcingtrue_train.loss.ave \
--tts_stats_dir exp/<teacher_model_dir>/decode_use_teacher_forcingtrue_train.loss.ave/stats \
--train_config conf/tuning/train_fastspeech2.yaml
ここで、--write_collected_featsは統計量計算の際に特徴量をキャッシュしておくオプション、--tts_stats_dirは統計量を保存するディレクトリを指定するオプションです。以上で、FastSpeech2の学習は完了となります。
より実践的な利用に向けて
ここまでで、事前学習モデルの使い方とレシピを利用したモデルの学習方法を紹介しました。より実践的な使い方として、ユーザーは自前のデータセットや新しいコーパスを用いたレシピを自作することもできます。詳細についてはESPnet2のレシピテンプレートを参照してください。
自前のデータセットに対するレシピの作成は初めは少々躓くことが多いと思います。しかしながら一度作ってしまえば、今後すぐにゼロから再現実験を行ったり、他の人に引き継いで実験してもらうといったことが容易に行えるようになります。そのため、実験の再現性を担保するためにもレシピ化することをおすすめします。
また、レシピを作ってしまえば、様々な学習の幅が広がります。例えば、公開済みの事前学習モデルを初期モデルとしてファインチューニングを実施するなどの処理も、学習コンフィグファイル(*.yaml)内で--pretrain_path及び--pretrain_keyオプションを利用することで簡単に実施できます。事前学習モデルパラメータの一部のみを読み込むこともできるため、モデルの一部分のみを初期化して学習したいといった場合にも柔軟に対応することできます。
TTSレシピでのファインチューニングを実施する例はHow to finetune the pretrained model?を参照してください。
むすび
本記事では、E2E音声処理ツールキットESPnet2を使った実践について概説しました。 ESPnetは日本人が中心となって開発を進めており、常に熱意ある開発者を募集しています。 興味のある方は、気軽に開発メンバーに連絡、もしくは、Github上での議論に参加してください!